Università Politecnica delle Marche
Sede di Ancona
![]()

Dipartimento di Ingegneria Informatica,
Gestionale e dell’Automazione
Corso di Laurea in Ingegneria Informatica e dell’Automazione
Analisi e implementazione di un algoritmo per la compressione di protocollo per reti wireless
Relatore:
Candidato:
![]()
Anno accademico 2005/2006
Indice generale
1 PREMESSA 4
1.1 Cosa sono le wireless lan 4
1.2 Vantaggi e svantaggi dell'approccio wireless 4
1.3 Tipologie di reti wireless 4
1.4 Composizione frame 5
1.5 Vantaggi compressione header 5
2 PROTOCOLLI 8
2.1 Architettura a livelli 8
2.2 Il protocollo IP 10
IPv4 10
2.3 Il protocollo TCP 11
Controllo congestione 12
2.4 Il protocollo UDP 13
3 PROTOCOLLO PPPOE 14
3.1 Descrizione 14
Fase di autenticazione 15
Fase di sessione 16
4 RP-PPPOE 17
4.1 Descrizione 17
4.2 Esecuzione 18
4.3 Fase di test 19
Netperf 19
Esecuzione 19
1° Fase di test 19
2° Fase di test 20
4.4 IPERF 21
Esecuzione 21
1° Fase di test 21
2° Fase di test 21
Conclusioni 22
5 ROHC 24
5.1 Descrizione algoritmo ROHC 24
Macchine a stati 26
Modalità operative 26
Gestione flussi in ingresso 26
Controllo degli errori 27
5.2 IMPLEMENTAZIONE ROHC 27
Implementazione ROHC 1° fase 27
Socket 28
Esecuzione 29
Implementazione ROHC 2° fase 31
Struttura Kernel 31
Codice aggiunto al kernel 33
Risultati 34
6 CONCLUSIONI 38
7 APPENDICE 39
7.1 Esempio pacchetto padi 39
7.2 Esempio pacchetto pado 40
7.3 Esempio pacchetto pppoe (sessione) 41
7.4 Sintassi netperf e netserver 42
7.5 Sintassi di iperf 43
7.6 Classificazione campi header 44
7.7 Listato del programma ROHC.c 45
7.8 Header del compressore (comp.h) 46
7.9 Header del decompressore (decomp.h) 47
7.10 Struttura sk_buff 48
7.11 Codice pskb_expand_head 49
7.12 Codice kernel compressione rohc 50
Le dichiarazioni e gli include: 50
Codice aggiunto in testa alla funzione dev_queue_xmit: 50
Codice aggiunto in testa alla funzione netif_receive_skb: 51
8 Bibliografia 52
In questa tesi ci occupiamo delle wireless lan (WLAN) e delle sue problematiche. Si darà prima una descrizione dei vari tipi di WLAN e delle varie tipologie di connessione tra i vari terminali con i punti di accesso alla rete (Access Point). Quindi si darà una descrizione dei protocolli maggiormente usati nelle reti per poter poi addentrarci nel miglioramento delle prestazioni di questi protocolli nelle reti wireless. Il problema principale di questo tipo di reti è la velocità dovuta soprattutto dalla sua limitazione di banda (byte trasmessi nell'unità di tempo); quindi bisogna cercare di sfruttare al massimo la banda disponibile limitando possibili ridondanze presenti nel flusso di dati trasferiti. Si sono valutate le prestazioni ottenute con il protocollo PPPOE (Point To Point Over Ethernet – protocollo per connessioni punto punto su link ethernet) che garantisce un accesso autenticato ma soprattutto che gestisce anche una semplice compressione dell'header (intestazione del pacchetto contenente informazioni quali indirizzo sorgente destinazione, tipo di pacchetto, ...). Questo permette di aumentare la banda utile a disposizione dell'utente finale che non è altro che la banda disponibile togliendo informazioni quali indirizzamenti, controlli di flusso, ecc. Questo protocollo è nato per reti cablate, quindi non risulta la soluzione ideale per le reti wireless.
A questo punto si è implementato un algoritmo in grado di comprimere l'header dei pacchetti e si è analizzata la sua efficienza.
Le comunicazioni wireless, ed in particolare il Wireless Networking, rappresentano una tecnologia in rapida espansione che consente all'utente un accesso a reti e servizi senza necessità di cablaggi tra terminale e punto di accesso alla rete. Tutto ciò può riguardare da vicino anche la telefonia cellulare che è anch'essa una rete punto punto wireless tra postazione base e stazione mobile.
In via teorica, gli utenti di una rete locale wireless vogliono usufruire degli stessi servizi e disporre delle stesse potenzialità a cui una rete cablata gli ha abituati.
La libertà di movimento è uno dei vantaggi maggiori dei terminali wireless nei confronti di quelli cablati, che sono statici quando connessi alla rete locale. La mobilità impone peró la necessità di considerare, a livello di sviluppo di sistemi, il problema dell' "handoff". In una wireless LAN ogni terminale ha un'area di copertura chiamata "cella", sfruttando il paradigma delle reti di telefonia cellulare. Se i terminali sono mobili, essi devono poter passare da una cella ad un'altra in maniera "trasparente" e senza perdere la connessione alla rete. Questo processo di passaggio è detto appunto handoff. Di solito in fase di progetto di nuovi edifici , si potrebbe considerare la possibilità di cablare gli ambienti dedicati alla presenza di nodi di una rete locale (uffici, centri di calcolo e cosi via). È ovvio che tutto diventa più difficile per edifici già esistenti e per cui non è stata prevista la suddetta possibilità. Quest'ultima situazione è invece facilmente gestibile con le reti locali wireless.
Possiamo distinguere due tipologie: WLAN o Wi-Fi e WiMax. Il Wi-Fi è stato progettato per reti locali senza fili ed è basata su specifiche “IEEE 802.11”. Le reti WLAN possono essere installate secondo due concetti differenti: peer-to-peer e ad infrastruttura.
Una WLAN in modalità peer-to-peer è una rete senza server, dove tutti i client sono allo stesso livello e dialogano tra loro. Questo tipo di installazione è frequente quando i client sono pochi, ma non è adatta ad una rete numerosa e concentrata a causa della sovrapposizione dei segnali e del conseguente calo di affidabilità.
Una WLAN in modalità infrastruttura si basa sull'esistenza di uno, o più, Access Point centrali, collegati ad una LAN cablata, che fungono da server smistando il traffico dei dispositivi della rete (client). Un Wireless Access Point (WAP) può essere costituito da un computer o da un dispositivo dedicato.
Il WiMax è specializzato nell'accesso senza fili a banda larga e si basa su specifiche “IEEE 802.16”. Per molti aspetti è un parente stretto del Wi-Fi con la piccola grande differenza che la sua portata di azione è pari a circa 50 km, contro le poche decine di metri del Wi-Fi. Utilizza uno spettro di banda compreso tra 2 e 11 Ghz per attività “domestiche” e da 10 a 60 Ghz per altre attività. Inoltre garantisce una banda indicativa di 70Mbit/s capace quindi di poter coprire l'equivalente traffico di migliaia di utenti con linea ADSL.
La composizione di un frame (flusso di byte inviato dalla scheda di rete) dati dello standard IEEE 802.11 rappresentato in figura 1.

Figura 1 Frame Ethenet
Questo frame contiene 4 indirizzamenti a 48 bit che però a seconda delle circostanze possono anche essere omessi; essi possono rappresentare:
Destination Address: contiene un indirizzo mac (indirizzo fisico assegnato in modo univoco ad ogni scheda ethernet) che identifica l'entità mac intesa come destinataria.
Source Address: contiene l'indirizzo mac che identifica l'entità mac che ha generato il frame.
Receiver Address: contiene un indirizzo mac che identifica l'entità mac che sarà l'immediata destinataria del frame corrente.
Trasmitter Address: contiene l'indirizzo mac che identifica la stazione (in genere l'access point) che sta trasmettendo il frame.
Il Frame Body rappresenta il payload del frame, cioè il pacchetto di livello Network (IP, ICMP,...) che contiene gli indirizzi della sorgente e del destinatario, il numero d'ordine del pacchetto, .... e quindi l'informazione che interessa l'utente finale.
Negli ultimi anni la comunità scientifica internazionale sta producendo un notevole sforzo per l'individuazione e la sperimentazione di possibili tecniche con cui ottimizzare il traffico di dati su tratte wireless. I link via radio soffrono di limitazioni in termini di banda disponibile e di rumorosità (quindi di Bit Error Rate). La tendenza attuale degli enti di standardizzazione è quella di cercare di uniformare l'intera connessione utilizzando il protocollo IP sia per le comunicazioni voce che per i dati. Inoltre dato che la larghezza di banda del canale radio è limitata e costosa, è importante che ne venga ottimizzato l'uso.
In quest'ottica, l'uso di una architettura basata su IP (Internet Protocol) non sempre si rileva ottimale; infatti questa architettura si basa su successivi incapsulamenti prodotti dai vari livelli per fornire servizi ai livelli superiori. Alla fine degli incapsulamenti viene a crearsi un header che risulta “inutile” per l'utente finale; quindi abbiamo che buona parte della banda richiesta dal servizio viene usata per la trasmissione di informazione inutile e/o ripetitiva.
Fin quando il pacchetto deve essere trasmesso su un link cablato a larga banda e con buone se non ottime caratteristiche di rumorosità, il “peso” dell'informazione di controllo rappresenta senz'altro un problema trascurabile. L'esatto contrario avviene invece quando il canale impiegato è wireless, dove la banda non solo è limitata, ma è anche costosa per l'operatore che deve fornirla all'utente.
Nel caso di comunicazioni di tipo real-time, il problema è veramente grande. Prendiamo ad esempio un classico servizio di Voice over IP: lo stack di protocolli prevede l'uso di RTP (Real Time Protocol) e UDP (User Datagram Protocol – protocollo di livello trasporto senza connessione e non affidabile) al di sopra di IP. Qui abbiamo un header (intestazione pacchetto) di 40 byte nel caso di IPv4 o di 60 byte per Ipv6; in genere il payload (informazione contenente effettivamente la voce) generato si aggira sui 20 byte per pacchetto, quindi il 67% con IPv4 (80% con IPv6) della banda richiesta dal servizio viene consumata per la sola trasmissione dell'header che tra l'altro sarà simile se non quasi identica a quella del pacchetto precedente.
La compressione dell'header può avvenire poco prima di mandare il segmento sul livello fisico come schematizzato in figura 2.
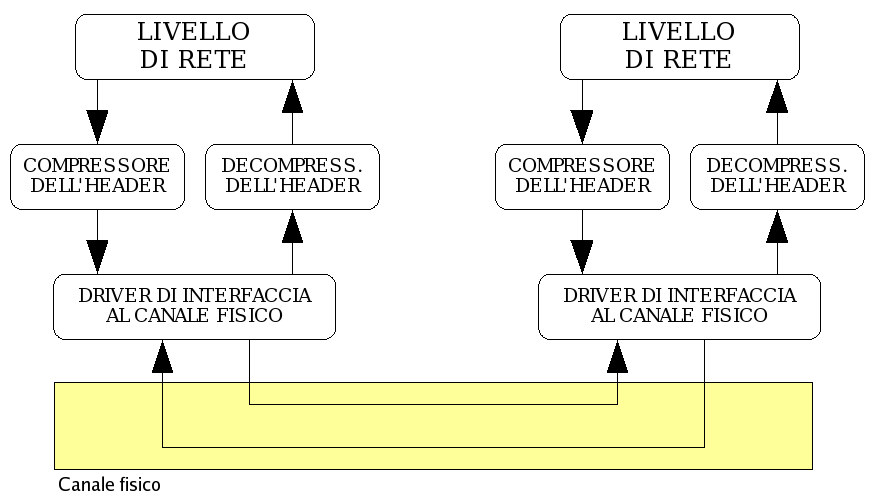
Figura 2
Possiamo definire l'overhead come il rapporto tra la lunghezza dell'header e l'intero pacchetto(header + payload).
![]()
Lo stesso problema, sia pure in modo meno rilevante, si presenta anche per trasferimenti di file con il protocollo FTP: in questi casi, infatti, la dimensione tipica dei segmenti TCP è di 576 byte, sui quali l'overhead è del 6,9% per IPv4 e del 10,4% per IPv6.
Infatti l'header generato da una pila protocollare composta da TCP e da IP, ha dimensioni minime pari a 20 byte per TCP più 20 byte per IPv4 (40 byte per IPv6).
Per tratte radio abbiamo che la riduzione della dimensione del pacchetto implica anche una minor possibilità per il pacchetto di arrivare danneggiato, dato che tratte radio hanno alti tassi di errori.
Riepilogando, i vantaggi che porta una compressione dell'header sono:
Risparmio banda: dovuto proprio alla riduzione dell'header del pacchetto che nel caso della compressione rohc (algoritmo che verrà illustrato in seguito) può essere ridotta fino a soli 2 byte (circa il 95% in meno !!).
Migliorare il FER (Frame Error Rate): a parità di caratteristiche di rumore (BER – Bit Error Rate), un canale che utilizza la compressione dell'header trasmette meno bit e quindi presenta un tasso d'errore sui pacchetti inferiore.
In passato sono stati realizzati altri schemi di compressione dell'header, ma tutti per collegamenti seriali a bassa velocità. Non risultano efficaci per applicazioni radio dato che il BER di un canale radio è di diversi ordini di grandezza superiore a quello di un cavo e inoltre il RTT(Round Trip Time, tempo medio impiegato da un pacchetto per arrivare a destinazione) è di circa 200ms.
Passiamo ora ad analizzare più in dettaglio la struttura dei protocolli principali per capire come sia possibile ridurre l'header.
L'architettura TCP/IP fu introdotta per la prima volta nel 1974 da Cerf e Kahn come modello di riferimento per la rete ARPANET, commissionata dal Dipartimento della Difesa statunitense. Il nome “TCP/IP” deriva dai due protocolli di base utilizzati: l'Internet Protocol (IP) ed il Transmission Control Protocol (TCP).
Il modello TCP/IP si sviluppa su una struttura gerarchica a livelli compatibile (con qualche differenza) con quella proposta per la prima volta con il modello OSI (Open System Interconnection) dell'International Standard Organization (ISO). La pila protocollare del modello ISO/OSI è mostrata in figura 3, mentre la gerarchia compatibile del TCP/IP è mostrata in figura 5.
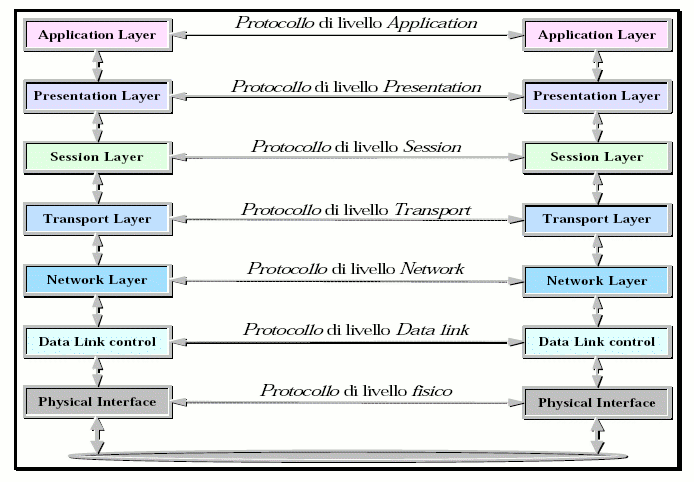
Figura 3 Modello ISO/OSI
Ogni livello è responsabile di aspetti diversi della comunicazione; il livello n su una macchina permette una conversazione con il livello n su un'altra macchina. La funzione di ogni livello è quella di fornire dei servizi al livello superiore.
Fra ogni coppia di livelli adiacenti esiste una interfaccia, la quale definisce quali operazioni primitive e quali servizi sono offerti da ciascun livello al livello superiore. Esistono 2 tipi di servizi: i servizi orientati alla connessione (connection-oriented) e i servizi non orientati alla connessione (connection-less).
I servizi connection-oriented sono modellati sulla base del sistema telefonico: l'utente del servizio prima stabilisce una connessione, poi la utilizza e infine la rilascia. La connessione agisce dunque come una specie di “tubatura”: il mittente introduce bit a partire da una estremità e il ricevente li riprende nello stesso ordine all'altra estremità; nessun altro può usare la stessa tubatura.
I servizi connection-less sono invece modellati sul sistema postale: ogni messaggio porta con sé l'indirizzo completo di destinazione e la porta, e viene condotto lungo il sistema indipendentemente dagli altri messaggi. Può accadere che l'ordine di arrivo dei pacchetti sia diverso dall'ordine con il quale sono stati trasmessi a causa della possibile diversa strada che può essere stata presa da un pacchetto nei confronti di un altro dovuto a instradamenti diversi.
Altra distinzione che può essere fatta sui servizi riguarda l'affidabilità. I servizi sono affidabili se garantiscono l'arrivo corretto a destinazione di tutti i dati; mentre sono non affidabili se non controllano l'effettivo arrivo a destinazione di tutti i dati.
L'architettura a livelli normalmente realizzata si basa solo sui livelli riportati in figura 4:
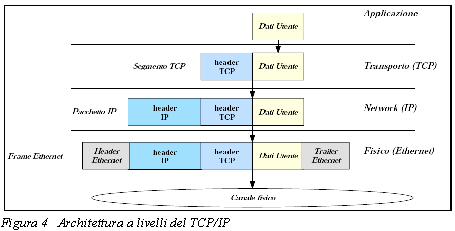

Quindi in realtà il protocollo TCP/IP prevede solo 4 livelli:
il livello di applicazione si occupa dei dei dettagli legati alla particolare applicazione;
il livello di trasporto è il primo che si occupa di gestire il flusso di dati a livello end-to-end. Abbiamo 2 differenti protocolli per questo livello: il TCP (Transmission Control Protocol) è un protocollo affidabile ed orientato alla connessione, mentre invece UDP (User Datagram Protocol) è un protocollo non affidabile e non orientato alla connessione.
il livello internet o network layer si occupa del “movimento” dei pacchetti all'interno della rete. In particolare, questo compito è affidato prima al protocollo IP (Internet Protocol), eventualmente affiancato dall'ICMP (Internet Control Message Protocol) e dall'IGMP (Internet Group Management Protocol). Il protocollo IP deve fondamentalmente scegliere il cammino dei pacchetti verso la destinazione; secondariamente, deve prendere anche alcuni provvedimenti per evitare condizioni di congestione della rete;
il livello fisico (data link) si occupa infine di tutti i dettagli per l'interfaccia con il mezzo fisico utilizzato per la comunicazione; il modello TCP/IP a questo livello si limita a specificare che l'host deve connettersi alla rete utilizzando un qualunque protocollo in grado di inviare pacchetti IP lungo di essa.
Occupa il livello 3 della pila ISO/OSI (Network Layer).
I due protocolli più comuni del livello rete sono l'x.25 ormai in disuso ed orientato alla connessione (connection oriented) e l'IP largamente diffuso e privo di connessioni (connection less).
L'x.25 invia prima un Call Request verso la destinazione, che può essere accettata o rifiutata. Se la connessione viene accettata, viene assegnato al chiamante un ID che sarà utilizzato nelle comunicazioni successive. Per questo motivo il protocollo x.25 viene definito un protocollo connection oriented.
Nel protocollo IP (Internet Protocol) invece il pacchetto viene spedito senza che sia necessario effettuare il setup dato che i pacchetti vengono instradati in maniera indipendente senza pre-instaurare un percorso.
IPv4 rappresenta la versione di codifica degli indirizzi IP attualmente in uso nell'Internet Protocol; è descritto nell'IETF RFC 791.
Il diagramma in figura 6 mostra la composizione dell'header del protocollo IPv4:

|
Versione |
Campo di 4 bit che descrive la versione del protocollo |
|
IHL |
Campo di 4 bit che definisce la lunghezza dell'intestazione |
|
Servizio |
Campo di 8 bit che definisce l'importanza del pacchetto |
|
Lunghezza totale |
Definisce la lunghezza totale del pacchetto (intestazione + dati) |
|
Identificazione, Flags, Offset fram. |
Campi usati nella frammentazione dei pacchetti |
|
TTL |
Tempo di permanenza massimo del pacchetto nella rete. Il suo valore diminuisce di uno per ogni router attraversato. |
|
Protocollo |
Definisce il protocollo di alto livello usato: TCP,UDP,... |
|
Checksum |
Per verificare la correttezza dei dati |
|
Indirizzo Mittente |
Campo di 32 bit contenente l'indirizzo IP del mittente |
|
Indirizzo Destinatario |
Campo di 32 bit contenente l'indirizzo IP del destinatario |
L'indirizzo IPv4 è formato da 32 bit ed è univoco sulla rete di cui fa parte.
Transmission Control Protocol (TCP) è il protocollo di trasporto su cui si appoggiano gran parte delle applicazioni Internet. Il TCP è un protocollo corrispondente al livello 4 del modello di riferimento OSI, e di solito è usato in combinazione con il protocollo di livello 3 IP. La corrispondenza con il modello OSI non è perfetta, in quanto TCP e IP nascono prima. La loro combinazione è indicata come TCP/IP ed è, alle volte, erroneamente considerata un unico protocollo.
Le caratteristiche principali del TCP sono:
La creazione di una connessione (protocollo orientato alla connessione)
La gestione di connessioni punto-punto
La garanzia che i dati trasmessi giungano a destinazione in ordine e senza perdita di informazione (tramite il meccanismo di acknowlegment e ritrasmissione)
Evita di congestionare la rete diminuendo la velocità di trasferimento se si accorge che la rete è quasi in saturazione
Una funzione di multiplazione delle connessioni ottenuta attraverso il meccanismo delle porte.
L'header di un segmento TCP è così strutturato:
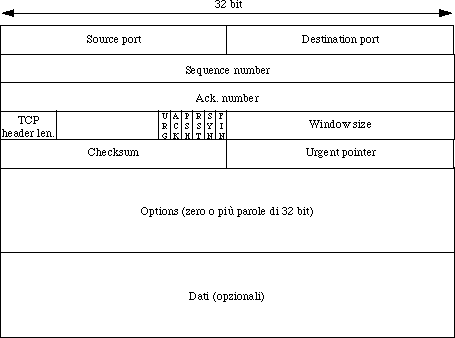
I campi dell'header hanno le
seguenti funzioni:
|
Source port, destination port |
identificano gli end point (locali ai due host) della connessione. |
|
Sequence number |
il numero d'ordine del primo byte contenuto nel campo dati. |
|
Ack. number |
il numero d'ordine del prossimo byte atteso. |
|
TCP header length |
quante parole di 32 bit ci sono nell'header (necessario perché il campo options è di dimensione variabile). |
|
URG |
1 se urgent pointer è usato, 0 altrimenti. |
|
ACK |
1 se l'ack number è valido (cioè se si convoglia un ack), 0 altrimenti. |
|
PSH |
dati urgenti (pushed data), da consegnare senza aspettare che il buffer si riempia. |
|
RST |
richiesta di reset della connessione (ci sono problemi!). |
|
SYN |
usato nella fase di setup della connessione:
|
|
FIN |
usato per rilasciare una connessione. |
|
Window size |
Contiene la dimensione del buffer di dati che il mittente può accettare. |
|
Checksum |
simile a quello di IP; |
|
Urgent pointer |
puntatore ai dati urgenti. |
Il protocollo TCP assume che, se gli ack non tornano in tempo, ciò sia dovuto a congestione della subnet piuttosto che a errori di trasmissione (dato che le moderne linee di trasmissione sono molto affidabili).
Dunque, TCP è preparato ad affrontare due tipi di problemi:
scarsità di buffer a destinazione;
congestione della subnet.
Ciascuno dei problemi viene gestito da una specifica finestra mantenuta dal mittente:
la finestra del buffer del ricevitore (quella di cui all'esempio precedente);
la congestion window, che rappresenta quanto si può spedire senza causare congestione.
Il mittente si regola sulla più piccola delle due.
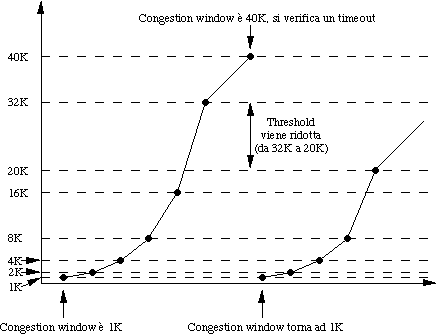
La congestion window viene gestita in questo modo:
il valore iniziale è pari alla dimensione del massimo segmento usato nella connessione;
ogni volta che un ack torna indietro in tempo la finestra si raddoppia, fino a un valore threshold, inizialmente pari a 64 Kbyte, dopodiché aumenta linearmente di 1 segmento alla volta;
quando si verifica un timeout per un segmento:
il valore di threshold viene impostato alla metà della dimensione della congestion window;
la dimensione della congestion window viene impostata alla dimensione del massimo segmento usato nella connessione.
Vediamo ora un esempio, con segmenti di dimensione 1 Kbyte, threshold a 32 Kbyte e congestion window arrivata a 40 Kbyte:
Il livello transport fornisce anche un protocollo non connesso e non affidabile: l'UDP. Esso è utile per inviare dati senza stabilire connessioni (ad esempio per applicazioni client-server).
L'header di un segmento UDP è molto semplice:

La funzione di calcolo del checksum può essere disattivata, tipicamente nel caso di traffico in tempo reale (come voce e video) per il quale è in genere più importante mantenere un'elevato tasso di arrivo dei segmenti piuttosto che evitare i rari errori che possono accadere.
Tecniche esistenti di compressione dell'header si basano sul protocollo PPP (Point To Point Protocol) che fornisce un metodo standard di trasporto di diversi tipi di protocolli su una connessione punto punto. La tecnica di compressione si basa sul trasmettere solo i campi dell'header che sono cambiati; quindi trasmette prima una serie di bit che informa quali campi dell'header sono cambiati e di seguito trasmette proprio i campi che hanno subito variazioni. Generalmente il protocollo IP viaggia su link diretti quali i modem che si occupano di stabilire una connessione punto punto su cui far viaggiare il PPP. Il PPPOE è una variante del PPP che permette di far viaggiare il protocollo PPP su una interfaccia ethernet.
Il protocollo PPPOE presenta 2 fasi: autenticazione e sessione.
Quando un host richiede una connessione, passa prima per la fase di autenticazione, dove si identifica il mac address ethernet e si stabilisce una SESSION_ID. Durante questa fase ci troviamo in un collegamento di tipo client-server; una volta autenticato il client, si passa ad una connessione peer-to-peer. Definiamo Host il client, e Access Concentrator il server. A questo punto si passa ad usare un'interfaccia virtuale PPP.
FRAME ETHERNET
Un frame ethernet è così composto:
0 1 2 3 4 5 6 7 8
9 0 1 2 3 4 5 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | DESTINATION_ADDR
| | (6 octets)
| |
| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | SOURCE_ADDR
| | (6 octets)
| |
| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | ETHER_TYPE (2
octets) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ ~
~ ~ payload
~ ~
~ +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | CHECKSUM
| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
DESTINATION_ADDR e SOURCE_ADDR
contengono l'indirizzo MAC della scheda ethernet e hanno una dimensione di 6
byte ciascuno (48 bit). Il DESTINATION_ADDR può contenere un indirizzo broadcast
( 0 x FF FF FF FF ) dove i pacchetti vengono ricevuti da tutte le postazioni
riceventi, oppure un indirizzo unicast che viene ricevuto unicamente da una
postazione.
L'ETHER_TYPE nel caso di una connessione PPPOE, contiene il valore di 0x8863 in fase di autenticazione e il valore 0x8864 nella fase di sessione.
ETHERNET PAYLOAD
Nel caso di PPPOE il payload ethernet è così composto:
0 1 2 3 4 5 6 7 8
9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | VER | TYPE |
CODE | SESSION_ID | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | LENGTH | payload
.................... +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Il campo “VER” indica la versione
di PPPOE. Nella versione di PPPOE attuale è impostato a 0x01.
Il campo “TYPE” è impostato a 0x01 nella versione di PPPOE attuale.
Il campo “LENGHT” indica la lunghezza del payload PPPOE.
La fase di autenticazione prevede 4 passaggi. Al loro completamento entrambi i nodi conoscono la SESSION_ID e i rispettivi MAC-ADDRESS per definire una sessione PPPOE univocamente.
Il PPPOE payload contiene zero o più tag.
Un tag è così definito:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| TAG_TYPE | TAG_LENGTH |
+---------------------------------------------------------------+
| TAG_VALUE ... ~
+---------------------------------------------------------------+
Per quanto riguarda la fase di autenticazione, abbiamo 5 tipi di pacchetti:
PADI (PPPOE ACTIVE DISCOVERY INITIATION)
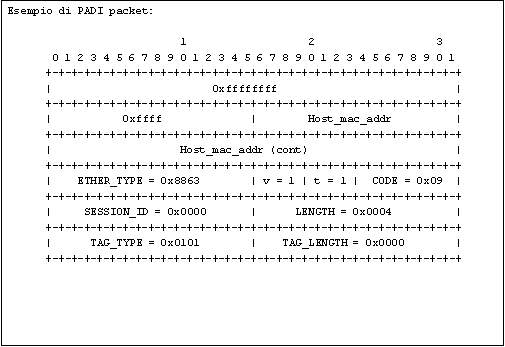
L'host manda un pacchetto PADI con il DESTINATION_ADDRESS (mac address) impostato sull'indirizzo di broadcast. Il campo “CODE” è impostato a 0x09 e il “SESSION ID” a 0x0000. Abbiamo anche un tag (SERVICE-NAME) che indica il tipo di servizio che l'host sta richiedendo.
In appendice si riporta esempio di pacchetto PADI (Appendice 7.2).
PADO (PPPOE ACTIVE DISCOVERY OFFER)
Quando il concentratore riceve un pacchetto PADI, risponde con un PADO. Il “DESTINATION_ADDRESS” è impostato in base al “SOURCE_ADDRESS” mandato dal pacchetto PADI. Il campo “CODE” è impostato a 0x07 e il “SESSION ID” sempre a 0x0000. Contiene un tag (AC-NAME) che indica il nome del concentratore , e un tag (SERVICE-NAME) che indica i servizi offerti dal concentratore.
In appendice si riporta esempio di pacchetto PADO (Appendice 7.3).
PADR (PPPOE ACTIVE DISCOVERY REQUEST)
L'host può ricevere più pacchetti PADO, ognuno con un AC-NAME o con SERVICE-NAME diversi. Ne sceglie uno e manda un pacchetto PADR; il “DESTINATION_ADDRESS” è impostato sull'indirizzo ethernet del concentratore. Il campo “CODE” è 0x19 e il “SESSION ID” è impostato sempre a 0x0000. Contiene un solo tag (SERVICE-NAME) con il nome del servizio che l'host richiede.
PADS (PPPOE ACTIVE DISCOVERY SESSION-CONFIRMATION)
Quando il concentratore riceve il pacchetto PADR, si prepara a iniziare la sessione PPP. Il “DESTINATION_ADDRESS” è impostato sull'indirizzo dell'host che ha mandato il PADR; il campo “CODE” è impostato a 0x65 e il “SESSION-ID” è impostato come valore univoco generato per questa sessione PPPOE.
Contiene un solo tag (SERVICE-NAME) che indica il servizio accettato.
PADT (PPPOE ACTIVE DISCOVERY TERMINATE)
Indica che la sessione è terminata e può essere inviato sia dall'host che dal concentratore.
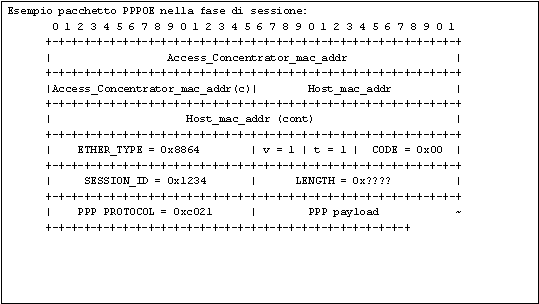
Arrivato il pacchetto PADS, si procede nella fase di sessione. Da qui in poi i dati vengono inviati con incapsulazione PPP.
La fase di sessione è così strutturata:
0 1 2 3 4 5 6 7 8
9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | VER | TYPE |
CODE | SESSION_ID | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | LENGTH | payload
.................... +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Nel payload è incapsulato il protocollo PPP.
Per valutare le prestazioni del protocollo PPPOE si può far riferimento al pacchetto software RP-PPPOE (Roaring Penguin PPPOE) disponibile sotto licenza GPL per il sistema operativo Linux. Questo pacchetto è nato per permettere gli utenti ADSL che necessitano del protocollo PPPOE di connettersi ad internet attraverso l'ambiente operativo linux.
RP-PPPOE è un pacchetto che mette a disposizione un server per accettare connessioni pppoe ed un client per instaurarle. Entrambi lavorano in concorrenza con PPPD che è un demone che gestisce le comunicazioni PPP. Questo software si pone tra il PPPD e il driver ethernet; comunica con il pppd attraverso una pseudo-tty (terminale virtuale) e con l'interfaccia di rete attraverso le socket-raw (libreria di funzioni messe a disposizione dal sistema operativo per comunicare con le interfacce di rete).

E' possibile avere sulla stessa linea più concentratori (server che accettano connessioni PPPOE), ciascuno con un “nome” diverso, e ciascun client può scegliere su quale connettersi.
Esistono due modi di funzionamento: modalità kernel e modalità user. In modalità kernel abbiamo bisogno di un kernel compilato con la funzionalità di PPPOE come modulo o inserito in modo statico nel kernel. In entrambi i casi abbiamo bisogno del pacchetto RP-PPPOE che a seconda dei casi si occupa di comunicare con il kernel oppure di instaurare direttamente la connessione agendo a livello user.
Per eseguire il server, occorre digitare il seguente comando: pppoe-server seguito da parametri. I parametri fondamentali sono:
-I <if-name>: per specificare l'interfaccia sulla quale accettare le connessioni.
-L <ip> : l'indirizzo da assegnare al macchina locale (server).
-R <ip> : l'indirizzo dal quale partire per assegnare gli indirizzi remoti.
-N <n> : stabilisce il numero di sessioni massime contemporanee.
-k : per stabilire se usare o meno la modalità kernel.
Per eseguire il client, basta semplicemente impartire il comando adsl-connect, uno script che si occupa di instaurare la connessione e di modificare la tabella di routing, in pratica è proprio come si deve instaurare una connessione adsl con un server provider.
La configurazione del server è contenuta in /etc/ppp/pppoe-server; la configurazione impostata è la seguente:

da notare come la riga require-pap sia commentata per evitare autenticazioni che fanno uso dello standard PAP. In questo modo non bisogna specificare nome utente e password per la connessione.
La configurazione del client può essere eseguita attraverso lo script adsl-setup, oppure editando il file /etc/ppp/pppoe.conf. L'unica opzione importante che può essere eseguita solo editando il file è quella di scegliere se il client utilizzerà la modalità kernel o la modalità user. Per utilizzare la modalità kernel, basta aggiungere la riga:
LINUX_PLUGIN=/etc/ppp/plugins/rp-pppoe.so
In questo modo, quando è ora di richiamare il pppd gli verrà detto di usare il plugin rp-pppoe.so che si occupa di comunicare con il kernel.
Quando la connessione viene stabilita, viene creata una nuova interfaccia di rete dal nome di ppp0 alla quale viene assegnato un indirizzo IP. Per il server, invece viene creata una interfaccia ppp per ogni connessione ognuna con un indirizzo point-to-point diverso a seconda di quale macchina client fa riferimento. Le prove sono state effettuate utilizzando due computer collegati attraverso un cavo cross ethernet.
In questa fase andiamo a verificare la banda a disposizione nel caso di un link ethernet in assenza e in presenza del protocollo PPPOE.
Per il test è stato utilizzato un noto programma di benchmark delle performance di rete, NetPerf. E' stato sviluppato inizialmente dalla HP agli inizi degli anni '90 come uno strumento che potesse essere usato per misurare vari aspetti delle prestazioni di reti IP. NetPerf prova a saturare il collegamento e restituisce il valore del throughput determinato in questo modo. Così facendo determina il throughput che un'applicazione avrebbe potuto ottenere se fosse stata utilizzata al momento della misura.
Deve essere installato su entrambi gli estremi del path del quale si vogliono misurare le caratteristiche. Funziona sulla base del modello client-server; viene stabilita prima una connessione per passare le informazioni di configurazione e immediatamente dopo, viene aperta una ulteriore connessione per realizzare la misura. Alla fine i risultati della misura vengono spediti attraverso la connessione di controllo e sono mostrati sia dalla parte del client che dalla parte del server.
Può fare diversi test, tra cui TCP_STREAM, TCPIPV6_STREAM e UDP_STREAM.
Esso consta di 2 eseguibili: netperf e netserver; netserver sarà il processo da eseguire sull'host ricevente, mentre netperf sull'host trasmittente. La porta socket sulla quale lavoreranno, può essere scelta a piacere mediante l'opzione “-p”.
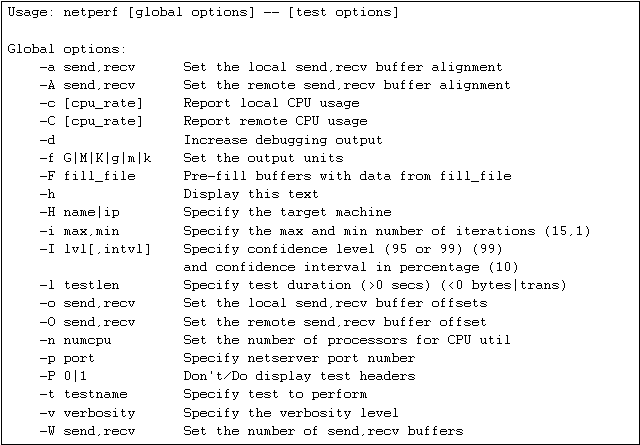
L'esecuzione si realizza attivando netserver sulla macchina che funzionerà da server e che quindi manderà i pacchetti, e netperf sulla macchina che funzionerà da client che riceverà i pacchetti. La sintassi dei due comandi con le relative opzioni è mostrata in appendice 7.5.
Come primo test, andremo a misurare le performance del PPPOE e le confronteremo con il normale protocollo TCP/IP senza nessuna incapsulazione. Questo su un link ethernet da 100Mbit/s.
Risultato con TCP/IP:
Recv Send Send Utilization Service Demand
Socket Socket Message Elapsed Send Recv Send Recv
Size Size Size Time Throughput local remote local remote
bytes bytes bytes secs. 10^6bits/s % S % S us/KB us/KB
87380 16384 16384 60.01 93.46 22.83 41.27 20.009 36.171
Possiamo notare come il throughput è di circa 93 Mbit/s.
Risultato con PPPOE:
Recv Send Send Utilization Service Demand
Socket Socket Message Elapsed Send Recv Send Recv
Size Size Size Time Throughput local remote local remote
bytes bytes bytes secs. 10^6bits/s % S % S us/KB us/KB
87380 16384 16384 60.01 62.49 85.35 97.15 111.896 127.361
Il throughput è sceso a circa 62 Mbit/s, ma notiamo anche che i processori sono saturi, cioè lavorano al 100%. Quindi sicuramente la nostra banda è limitata dalla velocità dei processori.
Questa volta facciamo un confronto con una connessione a 10 Mbit/s. Per portare la scheda di rete a 10Mbit, basta impostare come parametro media del modulo il valore “10baseT-HD” dove HD stà per half-duplex; oppure si può semplicemente impartire il comando mii-tool -A 10baseT-HD. In questo secondo caso ci pensa il comando a far ripartire il modulo.
Risultato con TCP/IP:
Recv Send Send Utilization Service Demand
Socket Socket Message Elapsed Send Recv Send Recv
Size Size Size Time Throughput local remote local remote
bytes bytes bytes secs. 10^6bits/s % S % S us/KB us/KB
87380 16384 16384 60.07 6.97 5.73 23.62 67.361 277.462
Possiamo notare come il throughput è 6,97 Mbit/s.
Risultato con PPPOE:
Recv Send Send Utilization Service Demand
Socket Socket Message Elapsed Send Recv Send Recv
Size Size Size Time Throughput local remote local remote
bytes bytes bytes secs. 10^6bits/s % S % S us/KB us/KB
87380 16384 16384 60.03 7.57 12.70 32.48 137.514 351.749
Il throughput è 7,57 Mbit/s. Anche quì l'utilizzo del processore è salito però solo dalla parte del trasmettitore.
Per eseguire una comparazione, si è usato anche un altro programma: “IPERF”. Questo programma di benchmark, presenta qualche funzione in più rispetto al precedente; ad esempio è possibile misurare le prestazioni cambiando le dimensioni della finestra TCP, fare misurazioni in UDP,....
Questa volta abbiamo un solo comando che a seconda dei parametri specificati, si trasforma in server o in client.
In appendice 7.5 la sintassi di iperf.
Con link a 100Mbit/s e con connessione TCP/IP normale otteniamo:
------------------------------------------------------------ Client connecting
to 172.16.16.142, TCP port 5001 TCP window size:
16.0 KByte (default) ------------------------------------------------------------ [ 3] local
172.16.16.141 port 56753 connected with 172.16.16.142 port
5001 [ 3] 0.0-10.0 sec
112 MBytes 93.5 Mbits/sec
Si può notare come la banda effettiva sia di 93.5 Mbit/s.
Con link a 10Mbit/s e sempre con connessione TCP/IP:
------------------------------------------------------------ Client connecting
to 172.16.16.142, TCP port 5001 TCP window size:
16.0 KByte (default) ------------------------------------------------------------ [ 3] local
172.16.16.141 port 59905 connected with 172.16.16.142 port
5001 [ 3] 0.0-10.0 sec
8.69 MBytes 7.28 Mbits/sec
In questo caso abbiamo una banda effettiva di 7.28 Mbit/s.
Con link a 100 Mbit/s e con protocollo PPPOE:
------------------------------------------------------------ Client connecting to 172.16.16.142, TCP port 5001 TCP window size: 16.0 KByte (default) ------------------------------------------------------------ [ 3] local 172.16.16.141 port 60666 connected with 172.16.16.142 port
5001 [ 3] 0.0-10.0 sec 98.0 MBytes 82.2 Mbits/sec
Abbiamo una banda reale di 82 Mbit/s
Con link a 10 Mbit/s e sempre con il protocollo PPPOE:
La banda reale è salita a 7.66 Mbit/s.
------------------------------------------------------------ Client connecting
to 172.16.16.142, TCP port 5001 TCP window size:
16.0 KByte (default) ------------------------------------------------------------ [ 3] local
172.16.16.141 port 60656 connected with 172.16.16.142 port
5001 [ 3] 0.0-10.0 sec
9.16 MBytes 7.66 Mbits/sec
Il protocollo PPPOE utilizza la compressione dell'header dato che è una derivazione del PPP. Infatti si serve dell'algoritmo di compressione “Van Jacobson” che interessa tutti i pacchetti della sola pila protocollare TCP/IP. Questo fa sì che le performance in reti lenti sia maggiore, anche se con link veloci abbiamo una cadenza di prestazioni dovuto all'elaborazione dell'header per la sua compressione che ha bisogno di potenza di calcolo.
Il PPPOE eredita molte caratteristiche dal PPP:
supporto multiprotocollo;
supporto all'autenticazione;
riconoscimento errori;
supporto all'indirizzamento IP dinamico.
Il PPP provvede all'incapsulazione, al link control e al network control.
Incapsulamento
L'incapsulamento permette di trasportare simultaneamente più protocolli sullo stesso collegamento, questo processo è stato progettato in modo da garantire la compatibilità tra hardware di vendor differenti. Il formato dei frame PPP è simile a quello utilizzato da HDLC (High-level Data Link Control).
Link Control
Il link control permette di avere a disposizione un metodo per tenere sotto controllo e quindi gestire la connessione PPP. LCP oltre a stabilire e terminare la comunicazione si occupa anche dell'autenticazione dei peer e del monitoraggio del suo corretto funzionamento.
Network Control Protocol
Grazie a NCP è possibile avere un protocollo di controllo per ogni livello rete supportato. NCP si occupa quindi di negoziare le opzioni del livello rete, come per esempio l'attribuzione dell'indirizzo IP utilizzato poi anche da altri protocolli TCP/IP trasportati.
Acronimo di Robust Header Compression.
La compressione di Van Jacobson (inizialmente realizzata per link seriali a bassa velocità) è adatta solo per link con bassi tassi di errori; altro punto a suo sfavore, è la possibilità di comprimere solo TCP/IP. Tutto questo non è adatto per reti wireless, dove i tassi di errori sono più elevati, e non sempre si ha a che fare solo con la pila protocollare TCI/IP.
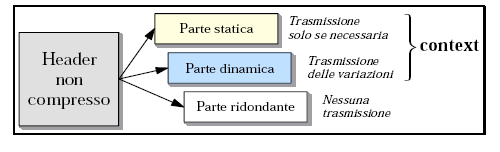
L'algoritmo ROHC è in grado di gestire ogni tipo di flusso di pacchetti che faccia riferimento ad una qualsiasi pila protocollare ma privilegia, nella sua versione originale, i flussi RTP/UDP/IP. La compressione sfrutta la ridondanza esistente tra i campi dell'header sia nel singolo pacchetto sia soprattutto tra pacchetti dello stesso flusso. Ai fini della compressione, ognuno degli header gestiti dall'algoritmo viene suddiviso in 3 parti: statica, dinamica, ridondante. Di volta in volta verrà trasmessa solo la parte dinamica e solo se necessaria anche la parte statica.
Abbiamo 4 profili di compressione, ognuno che definisce le regole di sintassi con cui si devono interpretare i tipi di pacchetti ROHC ricevuti:
Profilo 1 (ROHC RTP): comprime flussi di tipo RTP/UDP/IP (particolarmente usati nel VoIP)
Profilo 2 (ROHC UDP): comprime i flussi di tipo UDP/IP.
Profilo 3 (ROHC ESP): comprime i flussi protetti mediante protocollo di sicurezza dei dati.
Profilo 4 (ROHC IP): comprime i flussi che non appartengono a nessuno dei precedenti, ma che usano sempre il protocollo IP a livello di rete.
Profilo 0 (ROHC UNCOMPRESSED): comprime i pacchetti che non possono essere compressi dai profili precedenti.
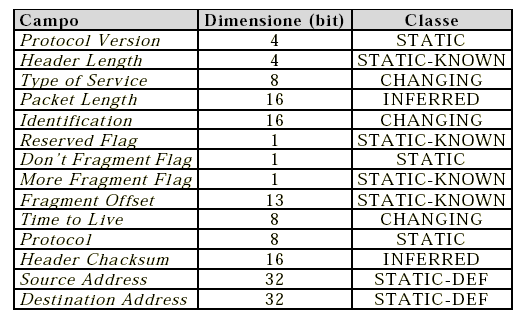
I campi dell'header di un qualsiasi protocollo vengono suddivisi in 5 categorie:
Inferred (ridondanti): contengono valori che possono essere dedotti da valori di altri campi (come ad esempio la dimensione del frame di livello fisico che ingloba il pacchetto di livello rete) e quindi non vengono mai trasmessi nel corso della connessione;
Static (statici): sono i campi che ci si attende rimangano costanti per tutta la vita di un dato flusso. In assenza di variazioni e/o di errori, tali campi possono essere trasmessi una sola volta, all'inizio della connessione;
Static-def (statici e caratteristici): si tratta sempre di campi statici, con in più la caratteristica di individuare un flusso di pacchetti, nel senso che tutti i pacchetti di uno stesso flusso hanno sicuramente gli stessi valori dei campi STATIC-DEF;
Static-know (statici e ben noti): anche questi campi sono statici e, in più, ci si aspetta che abbiano valori precisi e noti a priori, per cui non necessitano di essere trasmessi (come i campi ridondanti);
Changing (dinamici): questi campi assumono valori variabili nel corso di una stessa connessione, seguendo “modelli di variazione” non necessariamente costanti e non necessariamente noti a priori. Tali campi devono essere necessariamente trasmessi con ogni pacchetto (sia pure opportunamente codificati).
In appendice 7.6 si riporta la classificazione dei campi per i protocolli più comuni .
I campi che contengono valori costanti (ma non noti a priori) durante la vita di un flusso di pacchetti devono essere inviati, almeno teoricamente, solo una volta (campi STATIC), con il primo pacchetto della connessione. Si tratta dei seguenti campi:
IPv4 Version
IPv4 Source Address
IPv4 Destination Address
IPv4 Don't Fragment Flag (DF)
IPv4 Network Byte Order Flag (NBO)
IPv4 Random Flag (RND)
TCP Source Port
TCP Destination Port
I campi che cambiano solo occasionalmente in uno stesso flusso (campi RARELY-CHANGING) devono essere trasmessi inizialmente e deve inoltre essere previsto un modo efficiente per aggiornarli in caso di variazioni, trasmettendoli a valore pieno, eventualmente insieme alle relative variazioni.
I campi di questo tipo sono:
IPv4 Protocol
IPv4 Type Of Service (TOS)
IPv4 Time To Live (TTL)
TCP Window Size
TCP Urgent Pointer
TCP flag URG, ACK, PSH, RST, SYN, FIN
I campi critici, dal punto di vista della compressione, sono quelli che variano sempre, in modo più o meno regolare, tra un pacchetto e l'altro di uno stesso flusso (campi CHANGING): per essi si deve prevedere un efficiente meccanismo di aggiornamento (codificando opportunamente e trasmettendo solo le variazioni) e ci si deve anche preparare ad inviarli così come sono (as-is) in talune condizioni. Si tratta dei seguenti campi:
TCP Sequence Number
TCP ACK Number
IPv4 Identification (sequenziale con contatore unico)
I campi più facili da comprimere sono quelli che si comportano come dei contatori (campi CHANGING di tipo STATIC), nel senso che hanno delle variazioni fisse (tipicamente unitarie) da pacchetto a pacchetto. In questo caso, infatti, l'unico requisito da garantire è che il decompressore sia robusto nei confronti delle eventuali perdite di pacchetti, ottenendo al tempo stesso un buon livello di compressione.
Un Header IP di 20 byte (IPv4) può essere compresso fino a 1 byte alla massima compressione; Un header UDP/IP di 28 byte può essere compresso fino a 3 byte.
La compressione dell'header con l'algoritmo ROHC può essere vista come l'interazione tra due macchine a stati, ciascuna con 3 stati.
Compressore: ![]()
Decompressore:
![]()
Entrambe le macchine partono sempre nello stato più basso di funzionamento (minima compressione) e gradualmente si spostano verso gli stati a maggiore compressione.
Il compressore tende a permanere nello stato più alto, ma è costretto a transitare temporaneamente verso stati inferiori in corrispondenza di determinati eventi. Il decompressore ha transizioni verso stati inferiori solo in presenza di errori nel context. In condizioni ideali rimane sempre nello stato più alto.
Sono definiti 3 modi di funzionamento:
Modo unidirezionale (U-mode): i pacchetti viaggiano in una sola direzione, dal compressore al decompressore. Non abbiamo il feedback. Il funzionamento si basa sull'approccio ottimistico: il compressore passa in uno stato superiore (maggiore compressione) solo quando è sufficientemente sicuro che il decompressore abbia ricevuto le informazioni necessarie per decomprimere un pacchetto con maggiore compressione. Inoltre periodicamente il compressore deve aggiornare lo stato del decompressore portandosi in uno stato inferiore (minore compressione).
Modo bidirezionale Optimistic-Mode (O-mode): In questo caso abbiamo anche il canale di feedback utilizzato per richieste di aggiornamento contesto. Quindi il compressore può passare in uno stato superiore (maggiore compressione) attraverso il metodo ottimistico quando non arrivano richieste di aggiornamento contesto; oppure passa in uno stato a compressione inferiore se riceve un aggiornamento di contesto da parte del decompressore. L'intento è di massimizzare l'efficienza di compressione con un uso solo saltuario del canale di feedback.
Modo bidirezionale Reliable-mode (R-mode): in questo caso abbiamo un uso più intensivo del canale di feedback. Abbiamo transazioni in uno stato superiore (maggiore compressione) solo attraverso la ricezione di un ACK e transazioni in uno stato inferiore (minore compressione o perdita totale contesto) solo attraverso un NACK.
La capacità di gestire più flussi contemporanei in ingresso viene garantita dall'uso di una “tabella delle connessioni”. Ad ogni connessione viene associato tramite CID (Identificatore di contesto) un elemento della tabella, che contiene tutto ciò di cui il compressore ed il decompressore necessitano per svolgere i propri compiti sui pacchetti in ingresso.
Ogni elemento della tabella contiene:
CID;
Identificatore tipo di connessione;
Context;
Contatori;
Strutture dati per la codifica W-LSB (codifica usata per trasmettere campi che sono soggetti a piccoli cambiamenti dove viene trasmesso solo l'incremento rispetto al valore precedente);
Il requisito della robustezza dell'algoritmo, impone che la propagazione degli errori venga minimizzata effettuando dei controlli e degli eventuali tentativi di riparazione locale del context. Sono previsti diversi meccanismi per il controllo degli errori.
Il primo si basa sul CRC: solo i pacchetti decompressi che verificano il CRC (3,7 o 8 bit) possono aggiornare il context ed essere consegnati ai livelli superiori. Eventuali fallimenti del CRC sono imputabili a errori nella decodifica del W-LSB (wrap-around), oppure ad un context non valido (errori presenti nei pacchetti precedenti) e applica i relativi algoritmi di correzione.
Il secondo è l'algoritmo TWICE: nel caso si tratti di un pacchetto TCP, il decompressore verifica il “checksum TCP” del pacchetto appena decompresso; in caso negativo, tenta la riparazione su tutti i campi dinamici. Se il checksum fallisce ancora, il pacchetto viene scartato e sarà compito del layer superiore a garantire la sua ritrasmissione (dato che il TCP è un protocollo affidabile).
La comunità internet ha messo già a disposizione l'algoritmo per la compressione e decompressione dell'header sotto licenza GPL sfruttando le specifiche contenute nell'IEEE 3095 (Robust Header Compression). Questo algoritmo è composto da diverse funzioni tra cui troviamo le funzioni per l'effettiva compressione e decompressione del pacchetto.
Non abbiamo però a disposizione nessun kernel linux che si avvalga della possibilità di utilizzare questo algoritmo di compressione.
Il lavoro di implementazione è stato suddiviso in due parti:
Nella prima fase si implementa un algoritmo che permette di verificare il corretto funzionamento del compressore e del decompressore.
Nella seconda fase si prosegue con la vera e propria modifica del kernel linux che permette in questo modo di comprimere e decomprimere pacchetti in ingresso e in uscita in modo del tutto trasparente all'utente finale.
In questa fase si implementa un algoritmo per verificare il comportamento del compressore e del decompressore ROHC. L'obbiettivo del programma è quello di acquisire pacchetti provenienti dall'interfaccia ethernet per poi passarli al compressore. A questo punto ci ritroviamo con dei pacchetti compressi che vengono passati al decompressore il quale decomprime il pacchetto e quindi si effettua una comparazione tra i pacchetti di partenza e quelli che hanno subito la doppia elaborazione. Inoltre l'algoritmo si occupa anche di far scrivere alcune informazioni utili quali le dimensioni dei vari pacchetti sia originali che compressi, e di stampare su video il pacchetto originale, il pacchetto compresso e quello decompresso. Questo ci permette di verificare che le operazioni di compressione e decompressione non hanno in alcun modo alterato il pacchetto.
Per l'acquisizione dei pacchetti si è fatto uso delle Socket Raw (librerie messe a disposizione dal sistema operativo per lavorare sui pacchetti ethernet) che permettono la ricezione e la trasmissione di pacchetti di livello 2 (segmenti) o di pacchetti di livello 3. E' stata utilizzata la seconda opzione, in modo da sbarazzarsi del header di livello 2 (mac-address e type protocol). Il ROHC inizia la compressione dal livello IP (header IP compreso) tralasciando il livello datalink che è inglobato nell'hardware della scheda di rete e che quindi non si può modificare pena il non funzionamento del link.
Per aprire una socket:
int socket( int famiglia, int tipo, int protocollo ) ;
La chiamata socket può ritornare:
il socket descriptor se la chiamata è andata a buon fine.
-1 se la chiamata non ha avuto successo.
famiglia:
per svolgere I/O di rete, si deve effettuare la chiamata di sistema socket specificando il tipo di protocollo desiderato. Le famiglie di protocolli a disposizione sono le seguenti:
AF_UNIX : Protocolli interni di Unix.
AF_INET : Protocolli di internet.
AF_NS : Protocolli di Xerox NS.
AF_IMPLINK : livello di collegamento IMP
Il prefisso AF sta per "address family" (famiglia di indirizzi). Esiste poi un altro insieme di termini, con prefisso PF che sta per "protocol family" (famiglia di protocolli: PF_UNIX, PF_INET, PF_NS, PF_IMPLINK). Usare AF o PF è equivalente. IMP è l'acronimo di Interface Message Processor (elaboratore di messaggi di interfaccia);
tipo:
SOCK_STREAM : socket stream (TCP).
SOCK_DGRAM : socket di datagramma (UDP)
SOCK_RAW : socket rudimentale (IP)
SOCK_SEQPACKET : socket di pacchetto in sequenza.
SOCK_RDM : socket di messaggio consegnato affidabilmente (non implementato).
protocollo:
specifica il protocollo utilizzato dal socket, le principali costanti per i protocolli sono:
IPPROTO_UDP : UDP.
IPPROTO_TCP : TCP.
IPPROTO_ICMP : ICMP.
IPPROTO_RAW : IP.
Per leggere ora dal socket, possiamo usare una semplice istruzione di read come se leggessimo dallo standard input.
In apendice 7.7 è riportato il listato del programma.
Sempre in appendice sono riportati anche gli header del compressore (appendice 7.8) e del decompressore (appendice 7.9).
A questo punto si compila e si esegue il programma; inizialmente esso si mette in attesa di pacchetti che transitano sull'ethernet. Per far transitare qualche pacchetto basta aprire una qualsiasi pagina web e l'output ottenuto è il seguente:
OUTPUT DEL PROGRAMMA:
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=40
Pacchetto decompresso; dimensione=40
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=40
Pacchetto decompresso; dimensione=40
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=40
Pacchetto decompresso; dimensione=40
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=22
Pacchetto decompresso; dimensione=40
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=22
Pacchetto decompresso; dimensione=40
------------------------------
Pacchetto non compresso; dimensioni=48
Pacchetto compresso; dimensioni=38
Pacchetto decompresso; dimensione=48
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=30
Pacchetto decompresso; dimensione=40
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=30
Pacchetto decompresso; dimensione=40
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=22
Pacchetto decompresso; dimensione=40
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=27
Pacchetto decompresso; dimensione=40
------------------------------
Pacchetto non compresso; dimensioni=1500
Pacchetto compresso; dimensioni=1487
Pacchetto decompresso; dimensione=1500
------------------------------
Pacchetto non compresso; dimensioni=1500
Pacchetto compresso; dimensioni=1487
Pacchetto decompresso; dimensione=1500
------------------------------
Pacchetto non compresso; dimensioni=48
Pacchetto compresso; dimensioni=35
Pacchetto decompresso; dimensione=48
------------------------------
Pacchetto non compresso; dimensioni=40
Pacchetto compresso; dimensioni=27
Pacchetto decompresso; dimensione=40
Si può notare che una semplice comunicazione internet prevede una moltitudine di pacchetti di piccola dimensione, dove la compressione dell'header arriva a far guadagnare su qualche pacchetto fino a quasi il 50%. Infatti si è passati da 40 byte del pacchetto non compresso a 22 byte del pacchetto compresso. Si può notare anche come i primi pacchetti non subiscono una compressione perché si deve ancora stabilire il contesto per poi far passare il compressore e il decompressore in uno stato con maggiore compressione. Già dal 4° pacchetto in poi inizia la compressione spingendosi man mano ad un livello di compressione maggiore.
TOTALE byte senza compressione: 3496 byte
TOTALE byte con compressione: 3347 byte
Il profilo utilizzato è ROHC-IP, che provvede alla compressione del solo header IP. L'assenza di un profilo che comprime anche il TCP limita la sola compressione del protocollo IP lasciando inalterato il protocollo TCP.
Un miglioramento si avrà quando entrerà definitivamente in gioco IPv6, che prevede indirizzamenti non più a 32 bit, ma a 128 bit. Quindi si passa da un header IP di 20 byte ad uno di 40 byte, più eventualmente altre 20 byte del protocollo TCP se verrà creato anche un profilo che include il TCP e si potrà quindi pensare di comprimere un header TCP/IP da 60 byte.
Dato che le socket-raw lavorano a livello user, non abbiamo la totale trasparenza per le applicazioni. Per questo si è deciso di inserire nel kernel il compressore e il decompressore.
Questa stesura ha subito molte revisioni dato la complessità del kernel e la conoscenza non approfondita del livello fisico e dei suoi limiti. Una prima stesura è stata fatta con la kmalloc (simile alla malloc con l'unica differenza che lavora a livello kernel) che provvedeva a ricreare tutta la struttura che conteneva il pacchetto di livello fisico; in una seconda stesura ci si è serviti di una libreria per espandere il pacchetto (skb_expand_header) dato che in fase di ricezione il pacchetto andava decompresso e quindi espanso. Quindi si è deciso di inventare un nuovo Ether-Type di livello 2 con cui poter rappresentare pacchetti di tipo ROHC; non esiste ancora nessuna standardizzazione (IRFC) riguardo l'Ether Type per questo protocollo. Ad esempio il protocollo IP ha un Ether-Type uguale a 0x80, ICMP a 0x88, e quindi si è assegnato al rohc il valore di 0x70 che non è utilizzato da nessun protocollo. In questo modo i pacchetti rohc vengono decodificati solo da macchine che implementano questo protocollo, anche se in fondo questo protocollo incapsula un altro protocollo quale ad esempio IP. Quindi ci si è accorti di un problema presente in pacchetti di piccola dimensione, i quali partivano con una dimensione minore di 46 e arrivavano di dimensione proprio 46. Infatti dal IRFC dello standard ethernet si nota che la trama ethernet deve essere lunga almeno 64 byte, dimensione scelta proprio per far si che su un tratto di 2,5 Km (massima distanza coperta dall'ethernet) il tempo di propagazione sia almeno la metà del periodo minimo di trasmissione in modo che l'ethernet possa accorgersi di una collisione. Di questi 64 byte, 4 sono usati come inizio e fine trasmissione e 14 sono compresi nell'header del livello 2 (6+6 per i mac address e 2 per l'ether type); rimangono quindi 46 byte che è la dimensione minima del payload di livello 2. Per aggirare questo problema è bastato codificare la dimensione del pacchetto (solo se è inferiore a 46) nell'ether type.
L'ultimo problema è stato quello del checksum per i protocolli che supportano il checksum come ad esempio TCP e UDP. Il checksum del pacchetto che deve essere trasmesso viene calcolato poco prima di chiamare il driver della periferica. Ciò sembrerebbe una “distruzione” della separazione dei livelli protocollari; sicuramente è stato fatto così, perché il checksum del TCP è realizzato anche su un header fittizio che contiene gli indirizzi IP della sorgente e del destinatario. Quindi è bastato semplicemente far effettuare il calcolo del checksum prima di passare il pacchetto al compressore in modo che quando arriva al decompressore viene decompresso con il checksum giusto e può quindi essere riconosciuto correttamente dal kernel.
Di seguito viene riporatata la schematizzazione del percorso compiuto da un pacchetto ricevuto:
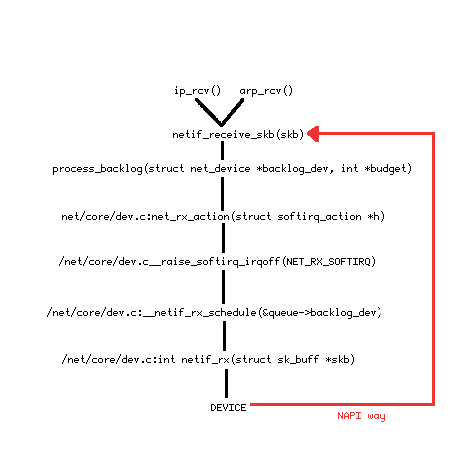
Il kernel 2.4 e il 2.6 presentano una leggera differenza a questo livello: il pacchetto nel kernel 2.4 attraversa tutte le funzioni evidenziate in nero; mentre nel 2.6, abbiamo il meccanismo NAPI.
Comunemente quando arriva una pacchetto l'interfaccia di rete lo mette in un buffer circolare chiamato ring utilizzando il DMA. Questo metodo ad alti carichi non permette alla CPU di elaborare altri dati, in quanto viene continuamente interrotto dagli interrupt. NAPI invece, appena arriva un pacchetto, disabilita gli interrupt per quel device e lo mette in polling. Ciò significa che sarà il kernel a controllare di tanto in tanto se sono arrivati pacchetti nuovi, e non verrà interrotto da continui interrupt.
In entrambe le situazioni alla fine il pacchetto viene passato alla routine netif_receive_skb il cui sorgente è in ./net/core/dev.c. Questa routine riceve come parametro un puntatore alla struttura skb (struttura che contiene il pacchetto e tutte le informazioni di cui necessita il sistema operativo per ogni pacchetto) definita in appendice 7.10.
Essa è realizzata come una coda, e presenta un puntatore all'skb precedente e uno a quello successivo. Il driver provvede a compilare soli i campi relativi a head, data, tail, end, la parte relativa al mac address...
Al momento che viene allocato l'skb, viene eseguita anche una kmalloc che ha il compito di riservare spazio di memoria dove verrà scritto il segmento proveniente dal livello 2 (dal driver della periferica).
Questo spazio di memoria riservato presenta la seguente struttura:
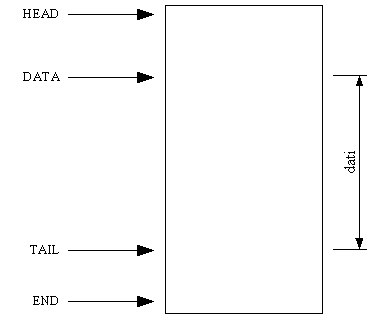
Nei buffer provenienti dal sistema operativo e diretti verso la scheda di rete (pacchetti in uscita), la porzione “dati” non contiene solo il payload del livello 2, ma anche il Destination Address, il Source Address e EtherType; questi 3 campi hanno una lunghezza complessiva di 14 byte (6+6+2). Mentre per quanto riguarda i pacchetti in ingresso, la porzione dati contiene solo il payload di livello due, dato che gli altri campi del frame verranno riempiti successivamente dal driver della scheda di rete.

Frame del livello 2
E' stata utilizzata la funzione pskb_expand_head presente nei sorgenti del kernel e precisamente in net/core/skbuff.c. E' una funzione molto semplice che non fa altro che espandere l'head o il tail della struttura skb.
Il codice della funzione pskb_expand_head è riportato in appendice 7.11.
Questa funzione si occupa anche di copiare la parte precedente al puntatore “data” e la parte successiva a “tail”. A questo punto resta solo da riposizionare il puntatore tail e end, e da modificare il contenuto tra i puntatori data e tail.
I parametri “nhead” e “ntail” rappresentano di quanto si vuole aumentare il corpo dell'intestazione e il corpo dati.
Prima di tutto abbiamo bisogno dei sorgenti di un kernel della famiglia 2.6; è stato testato sia sul kernel 2.6.5mdk fornito preconfigurato dalla Mandrake, e sia sul 2.6.13 (l'ultimo al momento disponibile) scaricato direttamente da http://www.kernel.org/ .
Il file del kernel modificato si trova nella directory net/core/dev.c che presenta le seguenti 2 routine:
int dev_queue_xmit (struct sk_buff *skb) : che si occupa del checksum e della trasmissione dei pacchetti al driver ethernet.
Int netif_receive_skb (struct sk_buff *skb) : che si occupa del trasferimento del pacchetto ai layer superiori, in base al tipo di EtherType e ai protocolli registrati. Se abbiamo più protocolli registrati con lo stesso EtherType, verrà sempre chiamato quello registrato per ultimo. Gli EtherType più comuni sono ICMP e IP.
Il codice aggiunto alla funzione che si occupa della trasmissione dei pacchetti può essere così schematizzato:
Viene controllato l'indirizzo di destinazione per vedere se applicare o meno la compressione. Inoltre viene controllata l'interfaccia verso la quale è diretto il pacchetto; se l'interfaccia è localhost non c'è bisogno di applicare la compressione.
Se sono verificate le condizioni precedenti, si passa alla chiamata della funzione di compressione che ci restituisce il pacchetto compresso e la sua dimensione.
Se size è maggiore di zero vuol dire che la compressione è andata a buon fine e possiamo quindi proseguire.
A questo punto si provvede a impostare il nuovo “ether type” che indica il tipo di pacchetto contenuto nel payload del livello 2. Bisogna inoltre controllare la dimensione del payload del pacchetto di livello 2 che non deve essere inferiore a 46 byte altrimenti si deve codificare la nuova dimensione nel campo “ether type” per poter essere correttamente decodificato in ricezione.
Il codice aggiunto in testa alla funzione che si occupa della ricezione dei pacchetti può essere così schematizzato:
Come prima cosa si controlla da quale interfaccia proviene il pacchetto e se si tratta di un pacchetto compresso (lo si vede dal campo ether type dell'header ethernet).
Si controlla se nel campo ether type è codificata anche la dimensione del pacchetto ed eventualmente si provvede a ristringere il pacchetto.
Si decomprime il pacchetto
Si trasforma il tipo di pacchetto da rohc a pacchetto IP cambiando l'ether type in 0x80.
Il codice è riportato in appendice 7.12.
Per i test è stato usato sempre il solito programma “IPERF”, e sono stati eseguiti test sia per quando riguarda l'UDP che per il TCP. Purtroppo non conoscendo strumenti adeguati, non si sono potuti effettuare test che coinvolgessero il profilo UDP-LITE sfruttato soprattutto per il VOIP (Voice Over IP). Per eseguire il test del TCP sono stati usati i comandi:
iperf -s sulla macchina che fungeva da server
iperf -c 172.16.3.2 -M mss_size sulla macchina che fungeva da client
Per eseguire il test in UDP:
iperf -s -u sulla macchina che fungeva da server
iperf -c 172.16.3.2 -l mss_size -u -b 100M sulla macchina che fungeva da client
Da notare l'impostazione 100M che indica il numero di pacchetti da trasmettere nell'unità di tempo. Infatti nel caso di UDP, iperf trasmette un certo numero di pacchetti al secondo per poi misurare quanti ne riceve; impostando questo valore a un numero abbastanza elevato si riesce a capire il throughput massimo.
Di seguito alcune definizioni:
MSS è l'acronimo di Maximum Segment Size, e rappresenta la dimensione del pacchetto senza considerare nessun header. Mentre MTU (Maximum Transmission Unit) rappresenta la dimensione del segmento, inclusi quindi gli header TCP o UDP e IP.
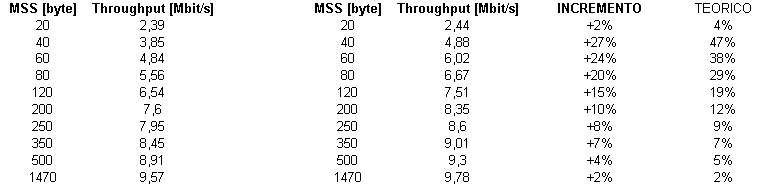
Per il calcolo dell'incremento teorico che si dovrebbe avere per il protocollo TCP/IP:
pacchetto originario: MSS + len_header_IP + len_header_TCP
pacchetto compresso: MSS + len_header_TCP + 2. Questo perché l'header IP viene ridotto a soli 2 byte. Con: len_header_IP = 20 e len_header_TCP = 20.
Si è tenuto sempre presente che la trama minima trasmissibile è di 46 byte.
TCP/IP TEST
Nella tabella sono riportati i dati ottenuti con un link a 10Mbit/s; la prima colonna rappresenta il throughput senza utilizzare l'algoritmo rohc, mentre la seconda sfruttando il ROHC. Quindi è riportato l'incremento ottenuto sperimentalmente e l'incremento teorico sempre tenendo conto della trama minima dello standard ethernet.

I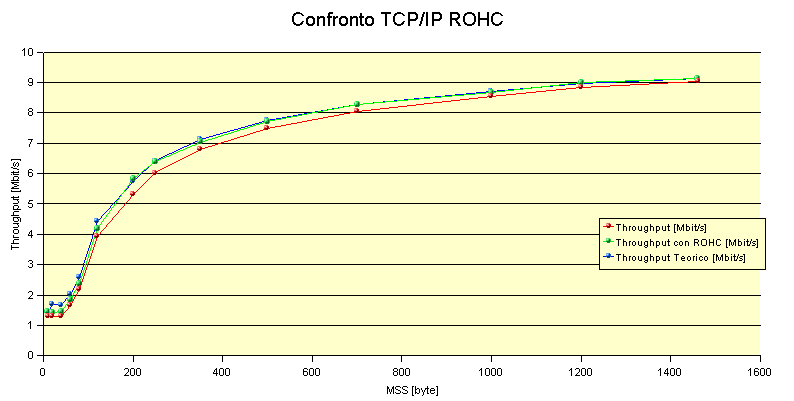
 ngrandimento
ngrandimento
Come si può notare dal grafico non abbiamo un incremento così rilevante per pacchetti di dimensione piccola come ci aspettavamo; questo è causato da un problema di IPERF che, con un MSS inferiore a 48, manda pacchetti di dimensione MTU pari a 88, come se avessimo impostato MSS a 48. In pratica non può trasmettere pacchetti di dimensione inferiore a 88 byte; ecco perché per un pacchetto con MSS pari a 20 byte abbiamo solo un incremento del 10% invece che del 30%. Questa però è solo una limitazione dell'IPERF, dato che con le socket raw si possono generare pacchetti anche con un MSS pari a 1 byte. Il valore più attendibile è quindi senz'altro quello teorico.
UDP/IP TEST
Ecco i risultati del test UDP.
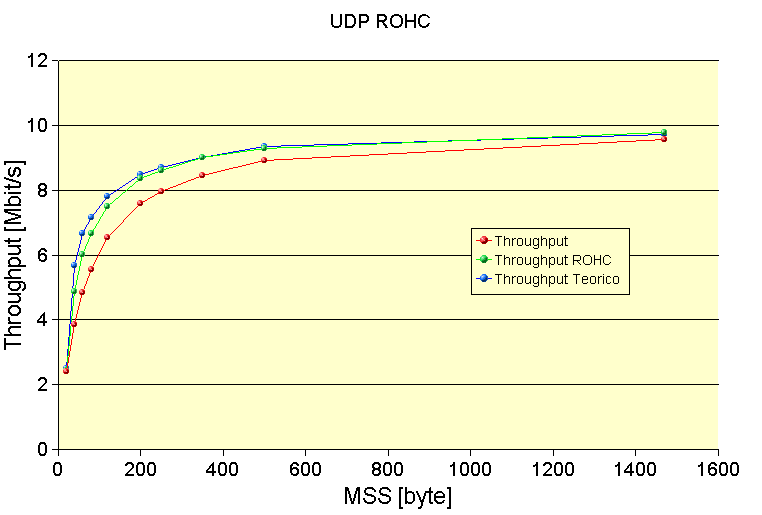
La compressione ROHC è applicabile quasi esclusivamente su collegamenti punto-punto, dato che è un protocollo non routabile. In realtà potrebbe diventare routabile a meno di avere un router che sia in grado di instradare correttamente un pacchetto ROHC. Questo accade perché i router lavorano a livello 3 il quale viene però alterato e compresso nel caso di una comunicazione ROHC. E' stata realizzata anche una prova per vedere la compatibilità in una rete a collisione di due macchine ROHC, insieme ad altre macchine che non si avvalevano di questa compressione, e i risultati sono positivi. La successiva prova è stata quella di testare il funzionamento dell'algoritmo rohc tra più di 2 macchine; quindi è stato eseguito un test, e il risultato è positivo solo se tutte le macchine hanno l'IP FORWARD disabilitato. Infatti se quest'ultimo è abilitato si ha che l'indirizzamento di livello 2 non viene rispettato e si hanno delle collisioni tra i CID (identificativo del flusso) delle varie macchine.
L'algoritmo di compressione ROHC è indicato soprattutto per reti con tassi di errori molto elevati quali ad esempio la wi-fi o altri collegamenti via etere. Infatti il protocollo oltre a comprimere l'header ha anche la caratteristica di essere “robusto” dato che mette a disposizione 2 strumenti per la correzione degli errori oltre alla presenza dei feedback che consentono l'aggiornamento di tutto o parte del contesto del decompressore.
Il vantaggio nell'uso di questo protocollo sarà molto più alto quando prenderà il sopravvento l'IPv6 che usa header più grandi a causa dell'indirizzamento a 128 bit.
Di seguito la struttura di un pacchetto PADI dove il client chiede una connessione.

Di seguito l'esempio di un pacchetto PPPOE nella fase di sessione cioè quando l'autenticazione è completata. Comprende anche il livello fisico.
Di seguito riporto la sintassi di netperf:
Sintassi netserver:
Usage: netserver [options] Options: -h Display this text -d Increase debugging output -L name,family Use name to pick listen address and family for
family -p portnum Listen for connect requests on portnum. -4 Do IPv4 -6 Do IPv6 -v verbosity Specify the verbosity level
Classificazione dei campi dell'header IPv4:
Classificazione dei campi dell'header IPv6:
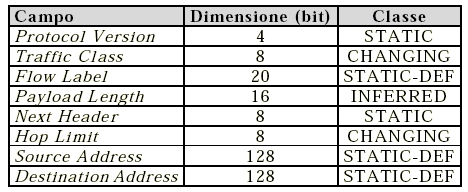
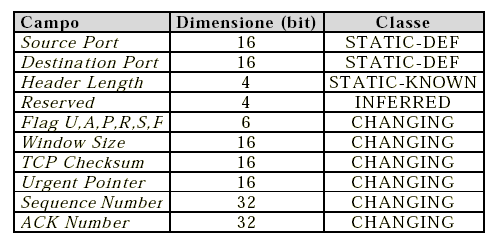
Classificazione dell'header dei campi TCP:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdlib.h>
#include <netinet/in.h
#include "testapp.h"
#include "comp.c"
#include "c_ip.c"
#include "c_uncompressed.c"
#include "c_udp.c"
#include "c_udp_lite.c"
#include "c_util.c"
#include "decomp.c"
#include "d_util.c"
#include "d_ip.c"
#include "d_udp.c"
#include "d_udp_lite.c"
#include "d_uncompressed.c"
#include "feedback.c"
#define MAXPACKAGESIZE 5000
#define DROP_PACKAGES 0
#define BIT_CHANGE 0
#define LOWER_DROP_PACKET 100
#define UPPER_DROP_PACKET 300
#include <sys/socket.h>
#define PKT_LEN 8192 //lunghezza massima pacchetto
int inputsocket;
char pacchettoingresso[PKT_LEN];
int debugmode = 0;
int feedback_size = 0;
static void *comp,*comp2;
int main(int argc, char *argv[]){
int x;
struct sd_rohc *decomp, *comp;
unsigned char ingresso[MAXPACKAGESIZE],uscita[MAXPACKAGESIZE];
unsigned char *p;
unsigned char alfa [PKT_LEN];
int size,cont;
p=alfa;
//inizializzazione socket
memset(pacchettoingresso, 0, PKT_LEN);
inputsocket = socket(PF_INET, SOCK_RAW, IPPROTO_TCP); //apertura socket in
input in modo raw 6->solo tcp
//inizializza compressore e decompressore
comp=rohc_alloc_compressor(15);
rohc_activate_profile(comp, 0);
rohc_activate_profile(comp, 2);
rohc_activate_profile(comp, 4);
rohc_activate_profile(comp, 8);
decomp=rohc_alloc_decompressor(comp);
//
for (cont=1;cont<=20;cont++){
size=read(inputsocket, p, PKT_LEN); //lettura pacchetto raw da socket
printf("\n------------------------------\nPacchetto non compresso; dimensioni=%d \n",size);
/*for (x=0; x<=size-1;x++){ //stampa in modo decimale il contenuto del pacchetto
printf("%d ",p[x]);
}*/
size=rohc_compress(comp,p,size,uscita,PKT_LEN);
printf("\n\nPacchetto compresso; dimensioni=%d \n",size);
/*for (x=0; x<=size-1;x++){ //stampa in modo decimale il pacchetto compresso
printf("%d ",uscita[x]);
}*/
memset(p, 0, PKT_LEN-1); //azzera stringa p
size = rohc_decompress(decomp,uscita,size,p,MAXPACKAGESIZE);
printf("\nPacchetto decompresso; dimensione=%d \n",size);
/*for (x=0; x<=size-1;x++){
printf("%d ",p[x]);
}*/
}
}
void feedbackRedir_piggy(unsigned char *ibuf, int feedbacksize){}
void feedbackRedir(unsigned char *ibuf, int feedbacksize){}
/* Allocate space for a compressor (transmit side) */
void *rohc_alloc_compressor(int max_cid);
/* Free space used by a compressor */
void rohc_free_compressor(struct sc_rohc *compressor);
/* Compress a packet */
int rohc_compress(struct sc_rohc *compressor, unsigned char *ibuf, int isize,
unsigned char *obuf, int osize);
/* Store static info (about profiles etc) in the buffer (no compressor is needed) */
int rohc_c_info(char *buffer);
/* Store compression statistics for a compressor in the buffer */
int rohc_c_statistics(struct sc_rohc *compressor, char *buffer);
/* Store context statistics for a compressor in the buffer */
int rohc_c_context(struct sc_rohc *compressor, int index, char *buffer);
/* Get compressor enabled/disable status */
int rohc_c_is_enabled(struct sc_rohc *compressor);
/* Is the compressor using small cid? */
int rohc_c_using_small_cid(struct sc_rohc * ch);
// Functions used by rohc's proc device
void rohc_c_set_header(struct sc_rohc *compressor, int value);
void rohc_c_set_mrru(struct sc_rohc *compressor, int value);
void rohc_c_set_max_cid(struct sc_rohc *compressor, int value);
void rohc_c_set_large_cid(struct sc_rohc *compressor, int value);
void rohc_c_set_connection_type(struct sc_rohc *compressor, int value);
void rohc_c_set_enable(struct sc_rohc *compressor, int value);
// These functions are used by the decompressor to send feedback..
// Add this feedback to the next outgoing ROHC packet:
void c_piggyback_feedback(struct sc_rohc *,unsigned char *, int size);
// Deliver received feedback in in decompressor to compressor..
void c_deliver_feedback(struct sc_rohc *,unsigned char *packet, int size);
struct sd_rohc * rohc_alloc_decompressor(struct sc_rohc *compressor);
void rohc_free_decompressor(struct sd_rohc * state);
int rohc_decompress(struct sd_rohc * state, unsigned char * ibuf, int isize, unsigned char * obuf, int osize );
int rohc_d_statistics(struct sd_rohc *, char *buffer); // store statistics about decompressor
int rohc_d_context(struct sd_rohc *, int index, char *buffer); // store statistics about a context
int rohc_decompress_both(struct sd_rohc * state, unsigned char * ibuf, int isize, unsigned char * obuf, int osize, int large);
int d_decode_header(struct sd_rohc * state, unsigned char * ibuf, int isize, unsigned char * obuf, int osize, struct sd_decode_data * ddata);
int d_decode_feedback(struct sd_rohc * state, unsigned char * ibuf);
int d_decode_feedback_first(struct sd_rohc * state, unsigned char ** walk, const int isize);
void d_operation_mode_feedback(struct sd_rohc * state, int rohc_status, int cid, int addcidUsed, int largecidUsed, int mode, struct sd_context * ctxt);
void d_change_mode_feedback(struct sd_rohc * state, struct sd_context * ctxt);
int rohc_ir_packet_crc_ok(unsigned char * walk, const int largecid, const int addcidUsed, const struct s_profile * profile);
int rohc_ir_dyn_packet_crc_ok(unsigned char * walk, const int largecid, const int addcidUsed, const struct s_profile * profile, struct sd_context * context);
void clear_statistics(struct sd_rohc * state);
void usergui_interactions(struct sd_rohc * state, int feedback_maxval);
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
struct sk_buff_head *list;
struct sock *sk;
struct timeval stamp;
struct net_device *dev;
struct net_device *input_dev;
struct net_device *real_dev;
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
} h;
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh;
union {
unsigned char *raw;
} mac;
struct dst_entry *dst;
struct sec_path *sp;
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[40];
unsigned int len,
data_len,
mac_len,
csum;
__u32 priority;
__u8 local_df:1,
cloned:1,
ip_summed:2,
nohdr:1;
/* 3 bits spare */
__u8 pkt_type;
__be16 protocol;
void (*destructor)(struct sk_buff *skb);
#ifdef CONFIG_NETFILTER
unsigned long nfmark;
__u32 nfcache;
__u32 nfctinfo;
struct nf_conntrack *nfct;
#ifdef CONFIG_BRIDGE_NETFILTER
struct nf_bridge_info *nf_bridge;
#endif
#endif /* CONFIG_NETFILTER */
#if defined(CONFIG_HIPPI)
union {
__u32 ifield;
} private;
#endif
#ifdef CONFIG_NET_SCHED
__u32 tc_index; /* traffic control index */
#ifdef CONFIG_NET_CLS_ACT
__u32 tc_verd; /* traffic control verdict */
__u32 tc_classid; /* traffic control classid */
#endif
#endif
/* These elements must be at the end, see alloc_skb() for details. */
unsigned int truesize;
atomic_t users;
unsigned char *head,
*data,
*tail,
*end;
};
int pskb_expand_head(struct sk_buff *skb, int nhead, int ntail,
unsigned int __nocast gfp_mask)
{
int i;
u8 *data;
int size = nhead + (skb->end - skb->head) + ntail;
long off;
if (skb_shared(skb))
BUG();
size = SKB_DATA_ALIGN(size);
data = kmalloc(size + sizeof(struct skb_shared_info), gfp_mask);
if (!data)
goto nodata;
/* Copy only real data... and, alas, header. This should be
* optimized for the cases when header is void. */
memcpy(data + nhead, skb->head, skb->tail - skb->head);
memcpy(data + size, skb->end, sizeof(struct skb_shared_info));
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++)
get_page(skb_shinfo(skb)->frags[i].page);
if (skb_shinfo(skb)->frag_list)
skb_clone_fraglist(skb);
skb_release_data(skb);
off = (data + nhead) - skb->head;
skb->head = data;
skb->end = data + size;
skb->data += off;
skb->tail += off;
skb->mac.raw += off;
skb->h.raw += off;
skb->nh.raw += off;
skb->cloned = 0;
skb->nohdr = 0;
atomic_set(&skb_shinfo(skb)->dataref, 1);
return 0;
nodata:
return -ENOMEM;
}
void *decomp=0, *comp=0;
#include "testapp.h"
#include "comp.h"
#include "comp.c"
#include "c_ip.c"
#include "c_uncompressed.c"
#include "c_udp.c"
#include "c_udp_lite.c"
#include "c_util.c"
#include "decomp.h"
#include "decomp.c"
#include "d_util.c"
#include "d_ip.c"
#include "d_udp.c"
#include "d_udp_lite.c"
#include "d_uncompressed.c"
#include "feedback.c"
#define offset 14
#define dest1 skb->data[offset+16]
#define dest2 skb->data[offset+17]
#define dest3 skb->data[offset+18]
#define dest4 skb->data[offset+19]
int data_offset,tail_offset,end_offset;
int x;
unsigned char *temp; int size;
temp = kmalloc(skb->len,GFP_ATOMIC);
memset(temp,0,skb->len);
//controlla l'indirizzo di destinazione per applicare o meno la compressione
if (dest1==172 && dest2==16 && dest3==3 && (dest4==2 || dest4==1) && skb->len > offset &&
skb->dev->ifindex==3){
//effettua compressione
size = rohc_compress(comp, skb->data + offset, skb->len - offset, temp, 5000);
printk("\nDimensione Originale: %d, Dimensione Compressa: %d",skb->len-offset,size);
if (size>0){
if (size >= 46){
(unsigned char)*(skb->data+offset-2)=7;
(unsigned char)*(skb->data+offset-1)=0;
}
else {
(unsigned char)*(skb->data+offset-2)=7;
(unsigned char)*(skb->data+offset-1)=size;
size=46;
}
#define diffdim size+offset-skb->len
pskb_expand_head(skb,0,diffdim,GFP_ATOMIC); //Espande l'header
memset (skb->data+offset,0,46);
skb->tail = skb->data+size+offset;
skb->len = size + offset;
memcpy(skb->data+offset,temp,size);
skb->ip_summed=0; //Indica che il checksum del pacchetto non è necessario
}
}
prg:
kfree(temp);
. . . . . . . . . . . . . . . . . . . .
Il pacchetto viene compresso solo se l'indirizzo di destinazione corrisponde a 172.16.3.1 o 172.16.3.2. In questo modo si può far comunicare il pc in una rete mista e comprimere solo se il destinatario compare nella lista.
Inoltre si controlla se la dimensione del pacchetto è inferiore a 46 e in tal caso la si forza a 46.
int x,chk;
unsigned char *temp2; int size;
if (comp == 0) {
crc_init_table(crc_table_3, crc_get_polynom(CRC_TYPE_3));
crc_init_table(crc_table_7, crc_get_polynom(CRC_TYPE_7));
crc_init_table(crc_table_8, crc_get_polynom(CRC_TYPE_8));
comp=rohc_alloc_compressor(15);
rohc_activate_profile(comp, 0);
rohc_activate_profile(comp, 2);
rohc_activate_profile(comp, 4);
rohc_activate_profile(comp, 8);
decomp=rohc_alloc_decompressor(comp);
}
temp2 = kmalloc(skb->len+40, GFP_ATOMIC); //GFP_ATOMIC
memset(temp2,0,skb->len+40);
if (skb->dev->ifindex != 3 || *(skb->data-2) != 7) goto proc;
if (*(skb->data-1) != 0) skb->len = *(skb->data-1);
size=rohc_decompress (decomp, skb->data, skb->len, temp2, 5000);
(unsigned char)*(&(skb->protocol)) = 8;
(unsigned char)*(&(skb->protocol) + 1) = 0;
(unsigned char)*(skb->data-2)=8;
(unsigned char)*(skb->data-1)=0;
if (size <= 0){
//pacchetto non decompresso
printk("\nPacchetto non decompresso");
}
else{
#define diffdim size-skb->len
pskb_expand_head(skb,0,diffdim,GFP_ATOMIC);
skb->tail = skb->data+size;
skb->len = size;
memcpy(skb->data,temp2,size);
skb->ip_summed = 2;
}
proc:
kfree(temp2);
. . . . . . . . . . . . . . . .
Al primo pacchetto ricevuto, viene inizializzato il compressore e il decompressore.
Per controllare se un pacchetto ricevuto è di tipo ROHC o meno, basta verificare l'ether type; se è pari a 0x70 vuol dire che si tratta di un pacchetto di tipo rohc e quindi lo decomprime e gli assegna 0x80 come ether type che corrisponde al protocollo IP. Dalla figura dell'header del frame di livello 2, si vede facilmente come il campo ether type lungo 2 byte si trova immediatamente prima del payload del frame; questo giustifica l'utilizzo di “*(skb->data-2)” e di “*(skb->data-1)”.
[1] Bormann C., RFC 3095 – Robust Header Compression (ROHC), July 2001
[2] Postel J., RFC 793 – Trasmission Control Protocol, September 1981
[3] Postel J., RFC 791 – Internet Protocol, September 1981
[4] Postel J., RFC 768 – User Datagram Protocol, August 1980
[5] L. Mamakos, K. Lidl, J. Evarts, D. Carrel, D. Simone, R. Wheeler, RFC 2516 – A Method for Trasmitting PPP Over Ethernet (PPPOE), February 1999
[6] W. Simpson, Ed., RFC 1661, The Point-to-Point Protocol (PPP), July 1994
[7] M. Engan, S. Casner, C. Bormann, T. Koren, RFC 2509, IP Header Compression over PPP,
July 1999
[8] Sito ufficiale Wikipedia (Enciclopedia libera), http://www.it.wikipedia.org/
[9] Sito http://openskills.info/
[10] Sito http://www.dizionarioinformatico.com/
